GRAM: Generative Radiance Manifolds for 3D-Aware Image Generation
CVPR 2022 (Oral Presentation)


Abstract
3D-aware image generative modeling aims to generate 3D-consistent images with explicitly controllable camera poses. Recent works have shown promising results by training neural radiance field (NeRF) generators on unstructured 2D image collections, but they still can not generate highly-realistic images with fine details. A critical reason is that the high memory and computation cost of volumetric representation learning greatly restricts the number of point samples for radiance integration during training. Deficient point sampling not only limits the expressive power of the generator to handle high-frequency details but also impedes effective GAN training due to the noise caused by unstable Monte Carlo sampling. We propose a novel approach that regulates point sampling and radiance field learning on 2D manifolds, embodied as a set of implicit surfaces in the 3D volume learned with GAN training. For each viewing ray, we calculate the ray-surface intersections and accumulate their radiance predicted by the network. We show that by training and rendering such radiance manifolds, our generator can produce high quality images with realistic fine details and strong visual 3D consistency.
Video
Overview
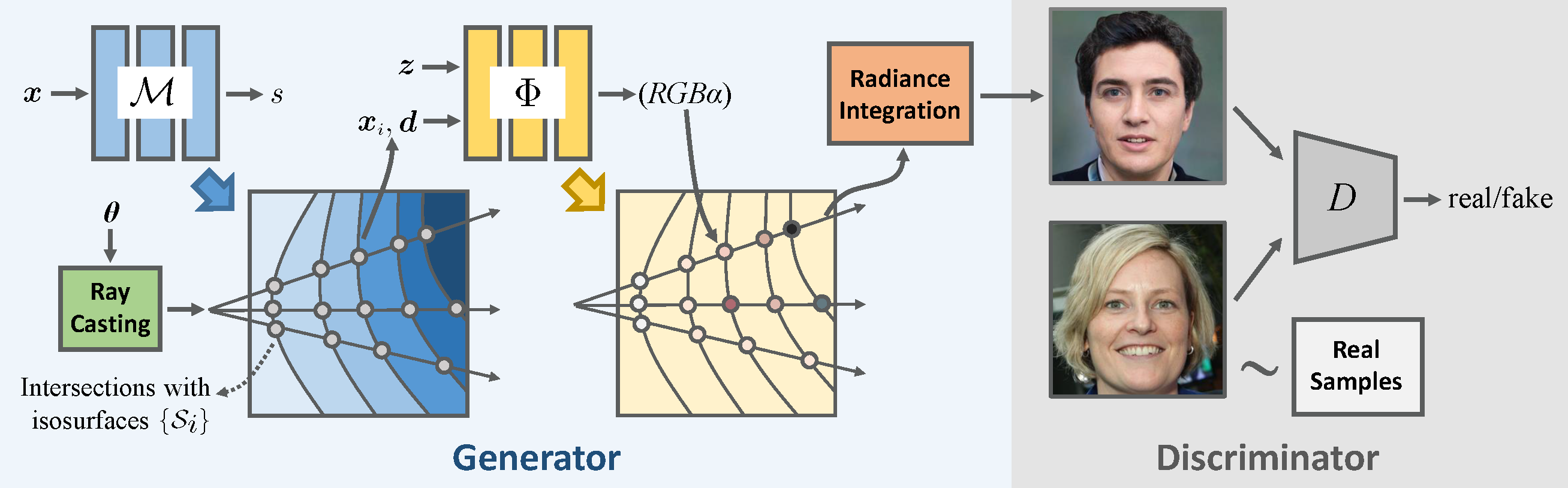
Overview of the GRAM method. The generator G consists of a manifold predictor M and a radiance generator Φ. M predicts multiple isosurfaces which define the input domain of Φ. The intersections between camera rays and the isosurfaces are sent to Φ for color and occupancy prediction. Images are then generated by compositing the color of the points along the ray.
Generation Results
GRAM is able to generate high-quality images with fine details. Moreover, it allows an explicit control of camera viewpoint and achieves highly consistent results across different views. It even maintains strong visual 3D consistency for very thin structures such as bangs of hair, eyeglass, and whiskers of cat.
GRAM achieves the best visual quality with realistic details and remarkable 3D consistency on multiple datasets comparing with previous 3D-aware image generation methods.
Manifolds Visualization
GRAM constrains point sampling and radiance field learning on 2D manifolds, embodied as a set of implicit surfaces. These implicit surfaces are shared for the trained object category, jointly learned with GAN training, and fixed at inference time.
3D Geometry Visualization
Although GRAM confines the input domain of the radiance field on 2D manifolds, we can still extract proxy 3D shapes of the generated objects using the volume-based marching cubes algorithm. It can be observed that GRAM produces high-quality geometry with detailed structures well depicted, which is the key to achieve strong visual 3D consistency across different views.
Responsible AI Considerations
The goal of this paper is to study generative modelling of the 3D objects from 2D images, and to provide a method for generating multi-view images of non-existing, virtual objects. It is not intended to manipulate existing images nor to create content that is used to mislead or deceive. This method does not have understanding and control of the generated content. Thus, adding targeted facial expressions or mouth movements is out of the scope of this work. However, the method, like all other related AI image generation techniques, could still potentially be misused for impersonating humans. Currently, the images generated by this method contain visual artifacts, unnatural texture patterns, and other unpredictable failures that can be spotted by humans and fake image detection algorithms. We also plan to investigate applying this technology for advancing 3D- and video-based forgery detection.
Availability of Software
Per concerns about misuse of this method, the code is available for use under a research-only license.
Citation
@inproceedings{deng2022gram,
title={GRAM: Generative Radiance Manifolds for 3D-Aware Image Generation},
author={Deng, Yu and Yang, Jiaolong and Xiang, Jianfeng and Tong, Xin},
booktitle={IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2022}
}
Acknowledgements
We thank Harry Shum for the fruitful advice and discussion to improve the paper.
The website template was adapted from Mip-NeRF.