Framework
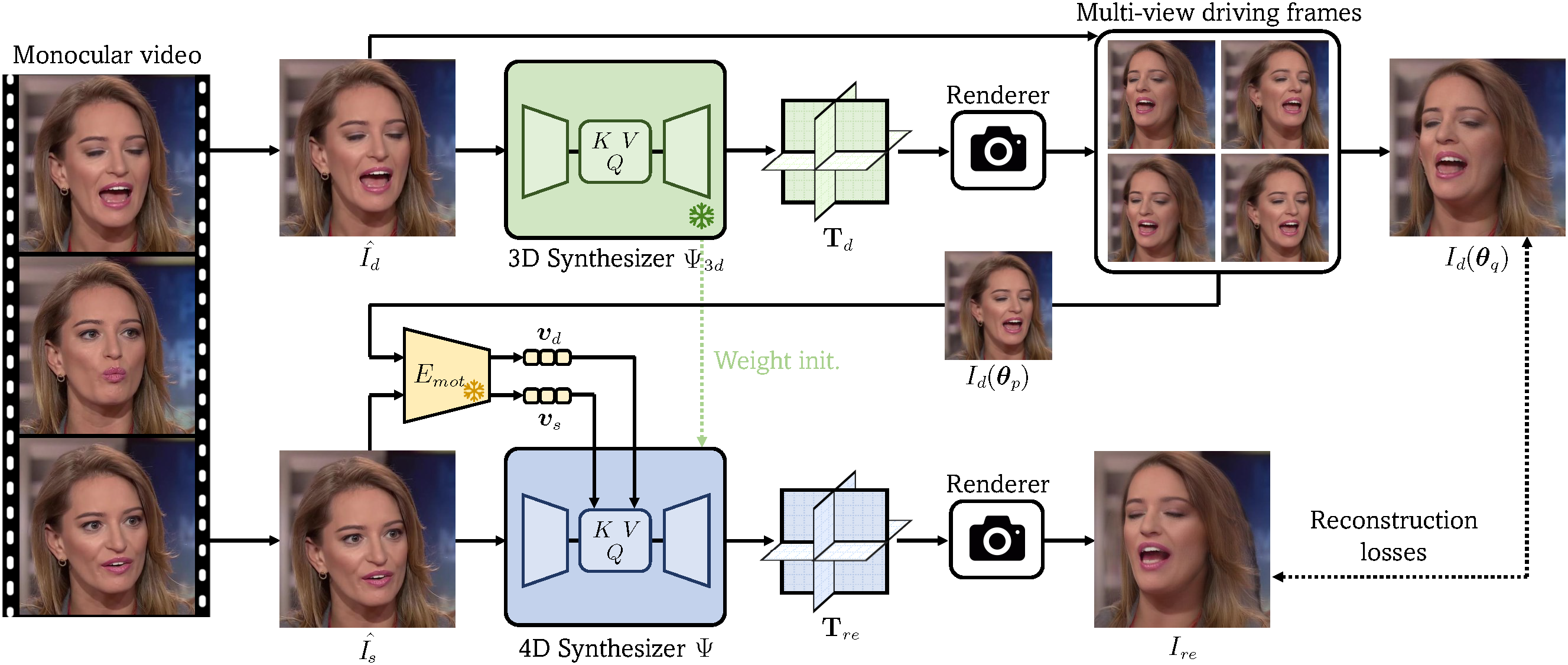
Overview of our approach. Given a monocular video sampled from the training set, we first leverage a pre-trained 3D synthesizer Ψ3d to turn each driving frame within the video into multi-view one, and then use the pseudo multi-view driving frames and a source frame sampled from the original video to perform cross-view self-reenactment for learning a feed-forward 4D head synthesizer Ψ. After training, Ψ can synthesize an animatable 3D head given two arbitrary images to provide the source appearance and driving motion, respectively.
Results
Talking Head Synthesis
Our method can synthesize vivid 4D talking heads via video-based reenactment. It faithfully reconstructs the source appearance meanwhile mimics the nuanced expressions in different driving videos.
Free View Rendering
Our method supports free-view rendering of the head avatars thanks to the underlying 3D representation. Use the slider below to linearly change the camera viewpoint.

Soure Image

Driving Image

Soure Image

Driving Image

Soure Image

Driving Image

Soure Image

Driving Image

Soure Image

Driving Image

Soure Image

Driving Image