Overview

For high-quality head avatar synthesis from a single image, we first learn a 4D generative head model from monocular images to synthesize large-scale 4D data of diverse identities, expressions, and poses. Then, we utilize the synthetic data to learn a one-shot 4D head reconstruction model in a data-driven manner.
Architecture
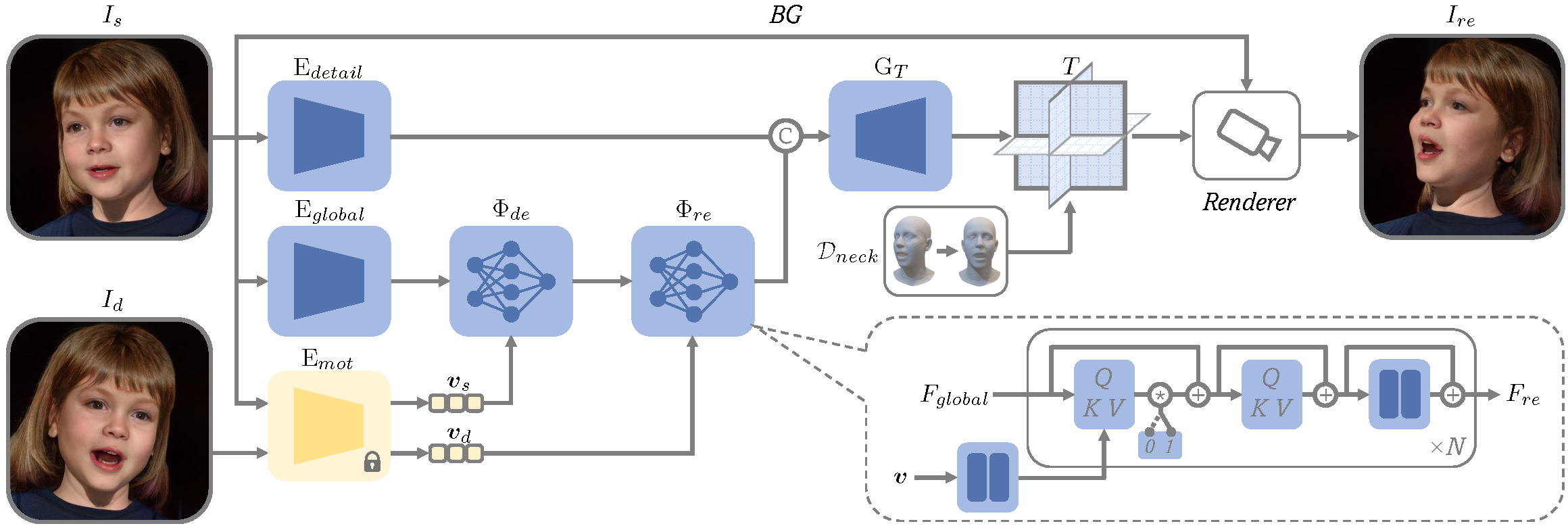
Architecture of our one-shot 4D head reconstruction model. An encoder Eglobal first extracts the appearance feature map of a source image Is. The feature map is then sent to a canonicalization and reenactment module Φ consisting of a de-expression module Φde and a reenactment module Φre sharing the same structure, which receives motion features from either Is or Id for expression neutralization or motion injection accordingly. The reenacted feature map is then concatenated with a detail feature map from another encoder Edetail, and sent to a decoder GT to synthesize a tri-plane T , bearing the appearance of Is and the motion of Id. With a FLAME-derived 3D deformation field Dneck to handle neck pose and a volumetric renderer with 2D super-resolution, T can be rendered to a reenacted image Ire at an arbitrary viewpoint. A U-Net is further introduced to handle background synthesis.
Results
Motion and View Inpterpolation
Here is an interactive viewer allowing for interpolations between motions (i.e. expressions and neck poses) and camera viewpoints. Drag the blue cursor around to change the attributes and observe the synthesized results in the middle.
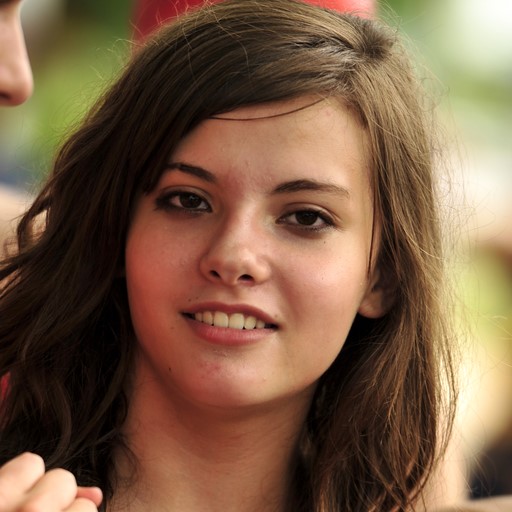 Input Image
Input Image

(Linear interpolation between motions and camera viewpoints.)
Geometry Visualization
We can extract geometries of the reconstructed head avatars via Marching Cubes thanks to the underlying 3D representation. The reasonable head geometries guarantee our strong 3D consistency under pose changes.

Comparisons
We compare our method with state-of-the-art one-shot head avatar synthesis approaches. Our method yields better reconstruction fidelity and maintains more reasonable head geometries under large pose variations. Compared to previous 3D-based methods, we support full head motion control with neck pose included as well as background separation.
More Results
We show more head synthesis results on monocular images. Our method synthesizes vivid talking heads of diverse identities.
BibTeX
@article{deng2023learning,
title = {Learning One-Shot 4D Head Avatar Synthesis using Synthetic Data},
author = {Deng, Yu and Wang, Duomin and Ren, Xiaohang and Chen, Xingyu and Wang, Baoyuan},
journal = {arXiv:2311.18729},
year = {2023},
}