|
Email: dengyu[at]microsoft.com Google Scholar Github I am currently a senior researcher at Microsoft Research Asia (MSRA). My research interests include 3D vision&generation, spatial understanding, and Embodied AI. Prior to that, I was a researcher at Xiaobing.AI working on realistic virtual avatar generation. Before joining Xiaobing, I had received my Ph.D. degree from Tsinghua University under the supervision of Prof. Harry Shum in 2022, and worked closely with Dr. Jiaolong Yang and Xin Tong as a research intern at MSRA from 2017 to 2022. Before that, I had received my B.S. from Department of Physics in Tsinghua University in 2017. |

|
|
|
|
|
Jianfeng Xiang, Xiaoxue Chen, Sicheng Xu, Ruicheng Wang, Zelong Lv, Yu Deng, Hongyuan Zhu, Yue Dong, Hao Zhao, Nicholas Jing Yuan, Jiaolong Yang arXiv 2025 [PDF] [Project] [Code] We propose TRELLIS.2, an image-to-3D generation method built on native and compact structured latents derived from a novel O-voxel 3D representation, designed for generating arbitary 3D assets with complex topologies and full PBR materials. |
|
|
Qixiu Li*, Yu Deng*, Yaobo Liang*, Lin Luo*, Lei Zhou, Chengtang Yao, Lingqi Zeng, Zhiyuan Feng, Huizhi Liang, Sicheng Xu, Yizhong Zhang, Xi Chen, Hao Chen, Lily Sun, Dong Chen, Jiaolong Yang, Baining Guo (* for equal contribution) arXiv 2025 [PDF] [Project] [Code] We propose VITRA, a novel approach for pretraining Vision-Language-Action (VLA) models for robotic manipulation using large-scale, unscripted, real-world videos of human hand activities. |
|
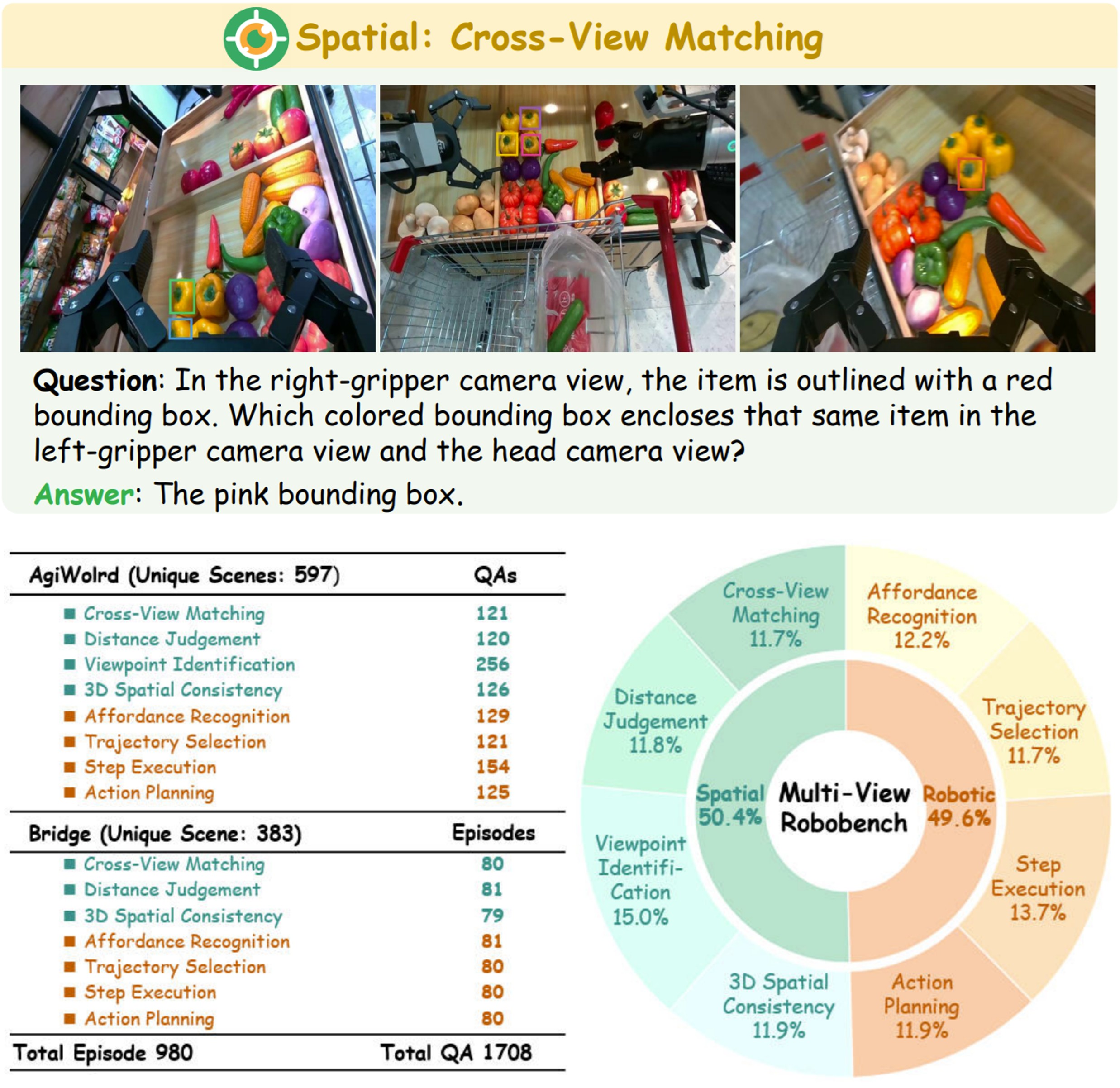
Zhiyuan Feng*, Zhaolu Kang*, Qijie Wang*, Zhiying Du*, Jiongrui Yan, Shubin Shi, Chengbo Yuan, Huizhi Liang, Yu Deng, Qixiu Li, Rushuai Yang, Arctanx An, Leqi Zheng, Weijie Wang, Shawn Chen, Sicheng Xu, Yaobo Liang, Jiaolong Yang, Baining Guo arXiv 2025 [PDF] [Project] [Code] We propose MV-RoboBench, a benchmark for evaluating the multi-view spatial reasoning capabilities of VLMs in robotic manipulation. |
|
|
Ruicheng Wang, Sicheng Xu, Yue Dong, Yu Deng, Jianfeng Xiang, Zelong Lv, Guangzhong Sun, Xin Tong, Jiaolong Yang 2025 Conference on Neural Information Processing Systems, NeurIPS 2025 [PDF] [Project] [Code] We propose MoGe-2, a monocular geometry estimation method with accurate metric-scale prediction and sharp details. |
|
|
Sicheng Xu*, Guojun Chen*, Jiaolong Yang, Yizhong Zhang, Yu Deng, Steve Lin, Baining Guo 2025 Conference on Neural Information Processing Systems, NeurIPS 2025 [PDF] [Project] We propose VASA-3D, a novel method for creating real-time life-like 3D talking head avatars from a single image. |
|
|
Jianfeng Xiang, Zelong Lv, Sicheng Xu, Yu Deng, Ruicheng Wang, Bowen Zhang, Dong Chen, Xin Tong, Jiaolong Yang 2025 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2025, Spotlight [PDF] [Project] [Code] We propose a native 3D generative model built on a unified Structured Latent representation and Rectified Flow Transformers, enabling versatile and high-quality 3D asset creation. |
|
|
Qixiu Li, Yaobo Liang, Zeyu Wang, Lin Luo, Xi Chen, Mozheng Liao, Fangyun Wei, Yu Deng, Sicheng Xu, Yizhong Zhang, Xiaofan Wang, Bei Liu, Jianlong Fu, Jianmin Bao, Dong Chen, Yuanchun Shi, Jiaolong Yang, Baining Guo arXiv 2024, [PDF] [Project] [Code] We propose a new advanced VLA architecture for robot manipulation, which leverages cognitive information extracted by powerful VLMs to guide action prediction of a specialized action module. |
|
|
Ruicheng Wang, Sicheng Xu, Cassie Dai, Jianfeng Xiang, Yu Deng, Xin Tong, Jiaolong Yang 2025 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2025, Oral Presentation [PDF] [Project] [Code] We present MoGe, a powerful model for recovering 3D geometry from monocular open-domain images. |
|
|
Yu Deng, Duomin Wang, Baoyuan Wang 2024 European Conference on Computer Vision, ECCV 2024, [PDF] [Project] [Code] We learn a lifelike 4D head synthesizer by creating pseudo multi-view videos from monocular ones as supervision. |
|
|
Yu Deng, Duomin Wang, Xiaohang Ren, Xingyu Chen, Baoyuan Wang 2024 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2024, [PDF] [Project] [Code] We propose a one-shot 4D head synthesis approach for high-fidelity 4D head avatar reconstruction while trained on large-scale synthetic data. |
|
Xingyu Chen*, Yu Deng*, Baoyuan Wang (* for equal contribution) 2023 IEEE International Conference on Computer Vision, ICCV 2023, [PDF] [Project] [Code] We propose a novel approach that enables a 3D-aware GAN to generate images with both state-of-the-art photorealism and strict 3D consistency. |
|
|
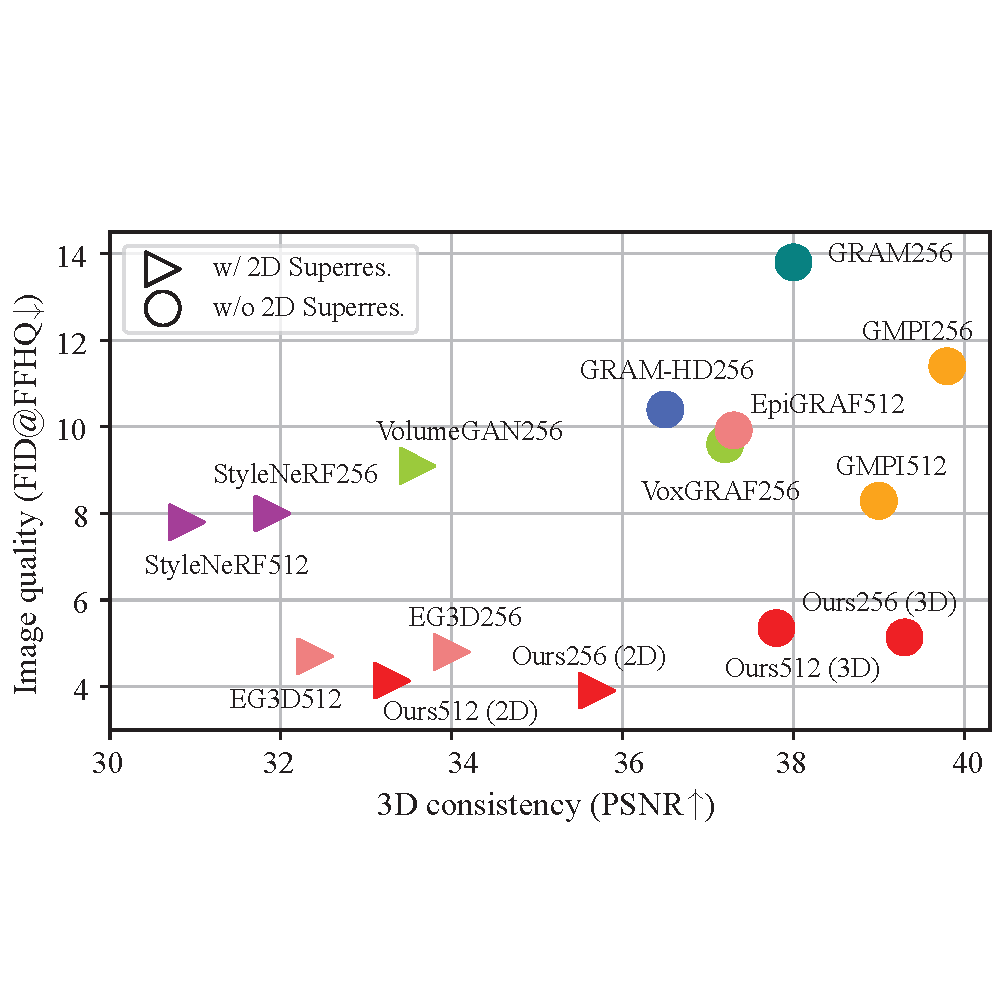
Jianfeng Xiang, Jiaolong Yang, Yu Deng, Xin Tong 2023 IEEE International Conference on Computer Vision, ICCV 2023, [PDF] [Project] [BibTeX] We propose GRAM-HD, a 3D-aware GAN that can generate photorealistic and 3D-consistent images at 1024x1024 resolution. |
|
|
Yu Deng, Baoyuan Wang, Heung-Yeung Shum 2023 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2023, [PDF] [Project] [BibTeX] We propose a learning-based approach for high-fidelity and 3D-consistent novel view synthesis of monocular portrait images. |
|
|
Duomin Wang, Yu Deng, Zixin Yin, Heung-Yeung Shum, Baoyuan Wang 2023 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2023, [PDF] [Project] We propose a one-shot talking head synthesis approach with disentangled control over lip motion, eye gaze&blink, head pose, and emotional expression. |
|
|
Yue Wu, Yu Deng, Jiaolong Yang, Fangyun Wei, Qifeng Chen, Xin Tong 2022 Conference on Neural Information Processing Systems, NeurIPS 2022, Spotlight [PDF] [Project] [BibTeX] We propose AniFaceGAN, an animatable 3D-aware GAN for multiview consistent face animation generation. |
|
|
Ziyu Wang, Yu Deng, Jiaolong Yang, Jingyi Yu, Xin Tong The 30th Pacific Graphics Conference, PG 2022, [PDF] [Project] [Code] [BibTeX] We propose a generative model for synthesizing radiance fields of topology-varying objects with disentangled shape and appearance variations. |
|
|
Yu Deng, Jiaolong Yang, Jianfeng Xiang, Xin Tong 2022 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2022, Oral Presentation [PDF] [Project] [Code] [BibTeX] We propose Generative Radiance Manifolds (GRAM), a method that can generate 3D-consistent images with explicit camera control, trained on only unstructured 2D images. |

|
Yu Deng, Jiaolong Yang, Xin Tong 2021 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, [PDF] [Code] [BibTeX] We propose a novel Deformed Implicit Field (DIF) representation for modeling 3D shapes of a category and generating dense correspondences among shapes with structure variations. |
|
|
Yu Deng, Jiaolong Yang, Dong Chen, Fang Wen, Xin Tong 2020 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2020, Oral Presentation [PDF] [Code] [BibTeX] We propose DiscoFaceGAN, an approach for face image generation of virtual people with disentangled, precisely-controllable latent representations for identity, expression, pose, and illumination. |

|
Sicheng Xu, Jiaolong Yang, Dong Chen, Fang Wen, Yu Deng, Yunde Jia, Xin Tong 2020 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2020, [PDF] [Code] [BibTeX] We propose a learning-based approach for recovering the 3D geometry of human head from a single portrait image without any ground-truth 3D data. |
|
|
Yu Deng, Jiaolong Yang, Sicheng Xu, Dong Chen, Yunde Jia, Xin Tong 2019 IEEE Conference on Computer Vision and Pattern Recognition Workshop on AMFG, CVPRW 2019, Best Paper Award [PDF] [Code] [BibTeX] We propose a novel deep 3D face reconstruction approach that leverages a robust hybrid loss function and performs multi-image face reconstruction by exploiting complementary information from different images for shape aggregation. |
|
|
|
Conference Reviewer: CVPR, ICCV, SIGGRAPH, SIGGRAPH Asia
Journal Reviewer: TPAMI, TVCG |
|
The website template was adapted from Jon Barron. |